行業主要上市公司:阿里巴巴 ( 09988.HK,BABA.US ) ; 百度 ( 09888.HK,BIDU.US ) ; 騰訊 ( 00700.HK, TCEHY ) ;科大訊飛 ( 002230.SZ ) ;萬興科技 ( 300624.SZ ) ;三六零 ( 601360.SH ) ;昆侖萬維 ( 300418.SZ ) ; 云從科技 ( 688327.SH ) ;拓爾思 ( 300229.SZ ) 等
多模態大模型的模型路徑
多模態大模型的探索正在逐步取得進展,近年來產業聚焦在視覺等重點模態領域突破。理想中的 "Any-to-Any" 大模型,Google Gemini、Codi-2 等均是處于探索階段的方案,其最終技術方案的成熟還需要在各個模態領域的路線跑通,實現多模態知識學習,跨模態信息對齊共享,進而實現理想中多模態大模型。現階段產業主要的工作還是聚焦在視覺等典型的重點模態,試圖將 Transformer 大模型架構進一步在圖像、視頻、3D 模型等模態領域引入使用,完善各個模態領域的感知和生成模型,再進一步實現更多模態之間的跨模態打通和融合。
 多模態大模型的圖像模型
多模態大模型的圖像模型
早在 2023 年 LLM 的流行之前,過去產業界在對于圖像的理解和生成模型領域已經打下了堅實的基礎,其中也產生了 CLIP、Stable Diffusion、GAN 等典型的模型成果,孕育出了 Midjourney、DALL · E 等成熟的文生圖應用。而更進一步,產業界也在積極探索將 Transformer 大模型引入圖像相關任務領域 ( ViT,Vision Transformer;DiT,Diffusion Transformer ) ,探索統一視覺大模型的建立,以及將 LLM 大語言模型與視覺模型進行更加密切的融合,包括近年來的 GLIP、SAM、GPT-V 都是其中的重點成果。
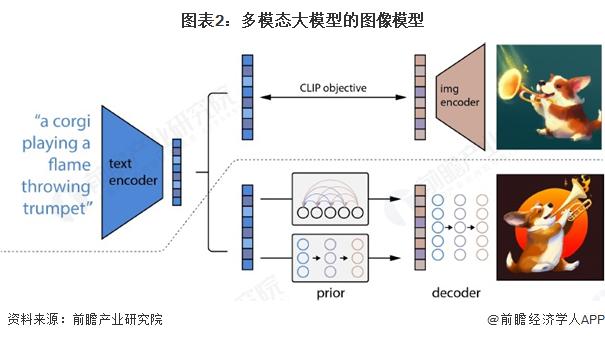 注:利用真實文本描述,通過 CLIP 生成的圖像特征
注:利用真實文本描述,通過 CLIP 生成的圖像特征
多模態大模型的視頻模型
由于視頻本質上是由很多幀的圖像疊加而成,因此本質上語言與視頻模態的融合和語言和圖像具有相當多的互通之處,產業界也在嘗試將圖像生成模型遷移到視頻生成,先基于圖像數據進行訓練,再結合時間維度上的對齊,最終實現文生視頻的效果。其中近年來也產生了 VideoLDM、W.A.L.T. 等典型的成果,并在近期也出現了 Sora 這樣具有明顯突破性效果的模型,其在視頻生成領域沿用了 Diffusion Transformer 架構,并在視頻類場景首次呈現出 " 智能涌現 " 的跡象。
視頻本質上是一系列圖像的連續展示,圖片生成是視頻生成的基礎。圖片生成的主流技術即擴散模型同樣也是視頻生成的主流技術,目前主流的文生視頻模型的技術路線為基于文生圖模型,通過在時間維度加入卷積或注意力,在生成的關鍵幀基礎上實現時序對齊得到視頻。在此基礎上,插幀 + 超分、初始噪聲對齊、基于 LLM 增強描述等方法均有助于增強時序對齊能力,實現更高質量的視頻生成。Zero-shot 領域的一系列研究則能夠實現無需訓練,直接將圖片生成模型轉化為視頻生成模型。
 多模態大模型的 3D 模型
多模態大模型的 3D 模型
實際上 3D 是由 2D+ 空間信息構成,因此類似于由圖像生成到視頻生成的延伸,2D 圖片的生成方法理論上也可以遷移到 3D 中。近年來產業界也在積極探索將圖像領域的 GAN、自回歸、Diffusion、VAE 等骨干模型在 3D 模型生成任務中的擴展,其中也產生了 3D GAN、MeshDiffusion、Instant3D 等重點的模型成果。但相比圖像和視頻生成,目前的 3D 模型生成技術還處于早期發展階段,相關模型的成熟度仍有較大提升空間。
3D 數據表征:包括網格 ( Mesh ) 、點云 ( Point clouds ) 等顯式表示,以及 NeRF ( Neural radiance fields,神經輻射場 ) 等隱式表示,還包括體素 ( Voxel grids,3D 空間中的像素 ) 這類混合表示,其中 NeRF 具有強大的三維表達能力和潛在的廣泛應用范圍,是 3D 數據表征的關鍵技術 ;
3D 數據集:包括 3D 數據 ( 數據量和精度有限 ) 、多視角圖片 ( 用途最為廣泛 ) 、單張圖片 ( 使用仍具有較大難度 ) 等。目前 3D 對象數據集仍然稀缺,代表性的數據集包括 ShapeNet ( Chang 等,2015 ) 構建了 5.1 萬個 3D CAD 模型,為 3D 數據集的充實做出開創貢獻 ;Deitke 等 ( 2023 ) 構建了 Objaverse 和 Objaverse-xl 數據集,分別有 80 萬和 1000 萬個 3D 對象 ;
3D 生成模型:前饋生成 ( 通過前向傳遞中直接生成結果 ) 、基于優化的生成 ( 每次生成需要迭代優化 ) 、程序生成 ( 根據規則創建 3D 模型 ) 、生成式新視圖合成 ( 生成多視角圖像 ) ;
3D 應用:包括 3D 人生成、3D 人臉生成、3D 物體生成、3D 場景生成等應用。
 多模態大模型的音頻模型
多模態大模型的音頻模型
語音相關的 AI 技術在過去多年中已經較為成熟,但近年來 Transformer 大模型在 AI 音頻領域的投入應用,還是成功推動了相關技術再上臺階,實現更優的音頻理解和生成效果,其中重點的項目成果包括 Whisper large-v3、VALL-E 等。語音技術沿革可分為三階段,深度學習驅動發展加速。語音技術主要向增強泛化能力的方向持續延伸,Transformer 架構引領語音技術迭代浪潮。泛化能力是指模型對于未經訓練的數據的適應能力,技術基礎來自具有強大學習能力的網絡架構和大量多樣化的數據訓練。語音模型泛化能力的增強主要體現在:從覆蓋單一語種到多語種和方言,從處理人聲到自然聲音、音樂,從簡單語音識別或合成到零樣本學習和多任務集成。
Omni 模型是利用 neural audio codec,主要是對音頻進行編碼以實現音頻合成。文本和聲波會先分別進入 embedding 和 adapter 進行編碼,再通過 Omni 模型進行合成和預測音頻的 token,最后通過擴散模型進行訓練,量化再用解碼器合成音頻。

來源:前瞻網















