在OpenAI文生視頻大模型Sora發布后,國內企業爭相入局,國產文生視頻大模型邁入加速階段。近日,又一國產視頻大模型加入戰局,快手“可靈”視頻生成大模型官網正式上線。相較此前各家放出的視頻大模型以展示視頻為主,本次亮相的可靈大模型不但效果對標Sora,且已在快手旗下的快影App開放邀測體驗。
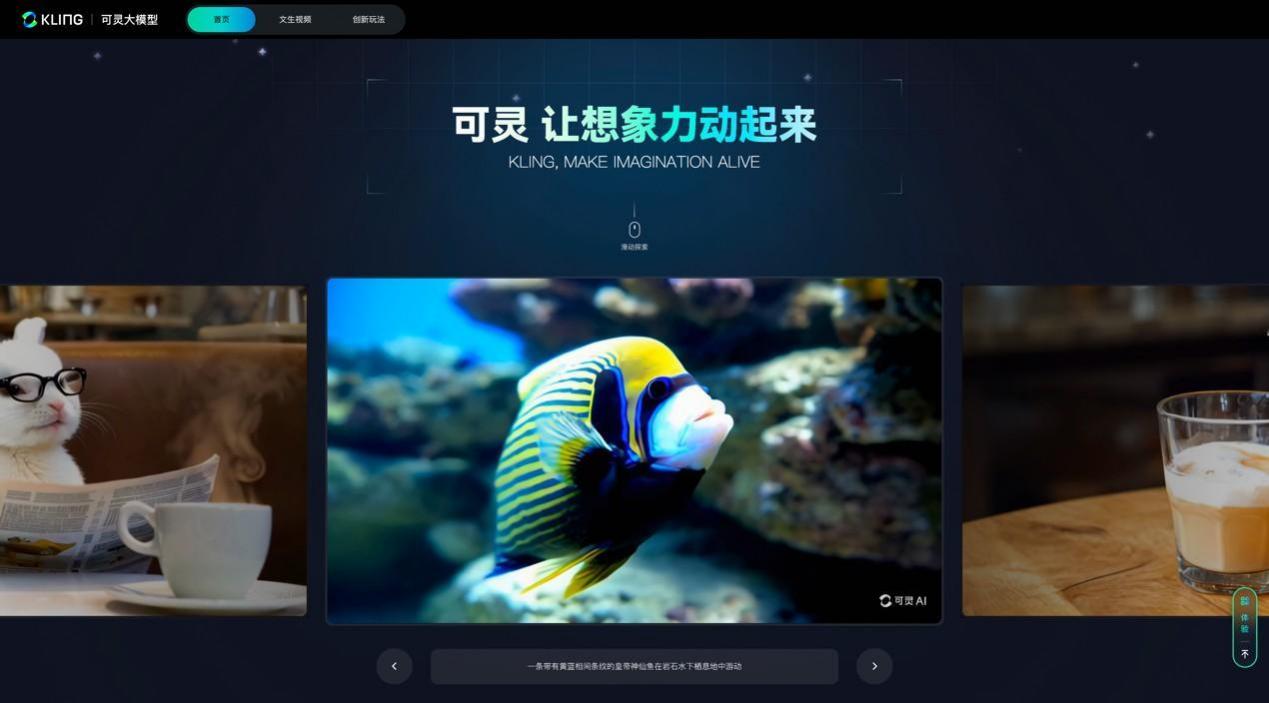
可靈大模型官網
作為短視頻領域頭部玩家,快手在短視頻視頻技術方面有多年的深入積累,其視頻生成大模型也有天然、廣泛的應用場景。可靈大模型為快手AI團隊自研,采用類Sora的技術路線并結合多項自研創新技術,具備諸多優勢:1、能夠生成大幅度的合理運動;2、能夠模擬物理世界特性;3、具備強大的概念組合能力和想象力;4、生成的視頻分辨率高達1080p,時長高達2分鐘(幀率30fps),且支持自由的寬高比。具體而言:
可靈大模型能夠生成大幅度的合理運動。可靈采用了3D時空聯合注意力機制,能夠更好地建模視頻中的復雜時空運動。因此,可靈大模型不僅能夠生成較大幅度的運動,且更符合客觀運動規律,能夠真正做到讓想象力動起來。下面宇航員在月球上奔跑的例子中,隨著鏡頭慢慢抬升,我們可以看到宇航員跑步的動作流暢輕盈,步態和影子的運動合理恰當。

prompt:一名宇航員在月球表面奔跑,低角度鏡頭展現了月球的廣闊背景,動作流暢且顯得輕盈
能夠模擬真實物理世界的特性。得益于自研模型架構及Scaling Law激發出的強大建模能力,可靈大模型為我們構建起了一個無限逼近現實的想象空間,無論是真實世界的光影反射,重力影響下的流體運動,還是與物理世界的交互,可靈大模型都能夠生成符合物理規律的視頻。下面是小男孩吃漢堡的生成視頻,一口咬下去,漢堡被咬掉一個大大的缺口,并在視頻中一直保持。可以看到小孩咀嚼漢堡的享受表情,臉部的肌肉動態非常逼真。

prompt:一個戴眼鏡的中國男孩在快餐店內閉眼享受美味的芝士漢堡
具備強大的概念組合能力和想象力。憑借模型對文本-視頻語義的深刻理解和基于 Diffusion Transformer 架構學到的強大概念組合能力,可靈大模型能夠將用戶豐富的想象力轉化為具體的畫面,讓創意觸手可及。下面的視頻展示了熊貓吉他手坐在湖邊彈著吉唱著歌的想象場景。

prompt:一只大熊貓在湖邊彈吉他
可靈大模型生成的視頻分辨率高達1080p、時長高達2分鐘(幀率30fps),且支持自由的輸出視頻寬高比。可靈大模型的自研3D VAE能夠將視頻編碼到緊湊的隱空間并解碼成帶有豐富細節的視頻,可以生成高達1080p分辨率30fps的視頻。得益于高效的訓練基礎設施、極致的推理優化和可擴展的基礎架構,可靈大模型能夠生成長達2分鐘的視頻。在推理過程中,還可以做到同樣內容輸出多種視頻寬高比。下面的視頻展示了分鐘級的視頻生成,我們可以跟隨鏡頭,陪伴小男孩騎自行車游覽花園,在一鏡到底中欣賞春夏秋冬四季的風景。

(完整視頻詳見可靈官網)
大模型的生成效果取決于數據的規模和質量、以及大規模訓練的效率。可靈大模型在研發過程中,配套建設了高效的大規模自動化數據解決方案,覆蓋了海量視頻挖掘、多維打標篩選、視頻描述增強、及數據驅動的效果質量評估等多個方面。在訓練過程中,采用了多種計算優化和通信優化方案,極大提升了GPU和網絡帶寬利用率,并通過自動故障檢測和failover等機制,提供了分鐘級故障恢復能力。保障了短時間內模型效果的快速提升。
快影App的AI創作功能中已正式開放文生視頻功能的邀測,支持創作者申請并體驗可靈大模型最新的文生視頻功能。圖生視頻功能也將于近期開放。
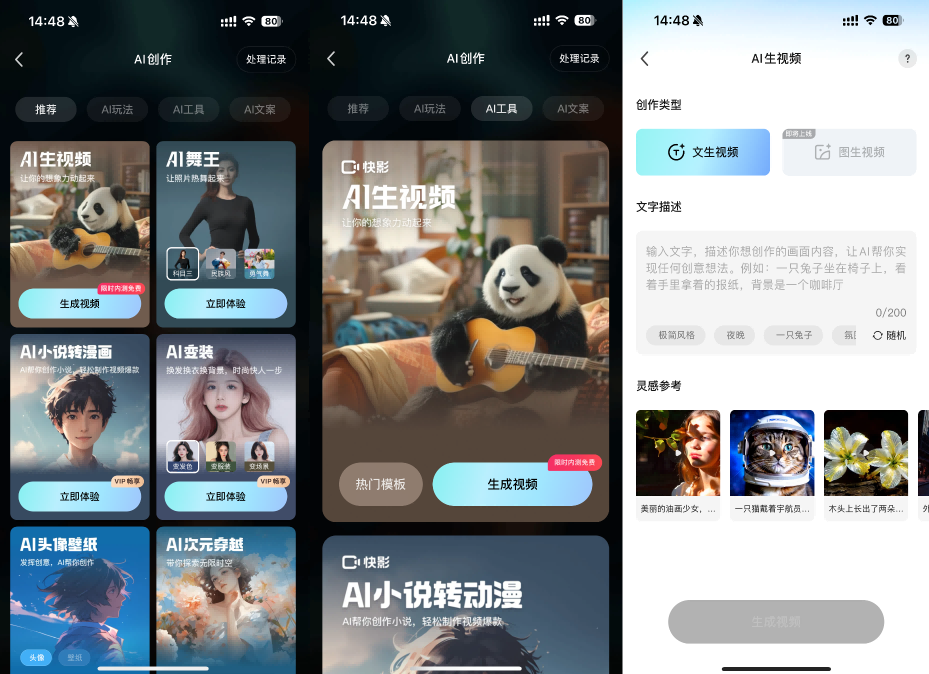
快影App還將在近期開放圖生視頻功能。基于可靈大模型,更多應用方向也已經或即將落地。例如,基于肢體驅動的“AI舞王”功能已在快手和快影App成功落地,用戶只需上傳一張全身或半身照片,即可體驗一鍵跳舞的樂趣。近期還將首發上線“AI唱跳”新玩法,可以同時驅動表情和肢體動作,僅需一張照片就能生成唱跳“愛你”的生動視頻。

隨著AI大模型時代來臨,作為頭部短視頻公司,快手已展開全面布局。公開資料顯示,快手已先后發布通用大語言模型“快意”、文生圖大模型產品“可圖”,還推出了Direct-a-Video、Video-LaVIT、I2V-Adapter、UNIAA等視頻關鍵技術,引發了廣泛關注。據悉,伴隨此次可靈大模型的發布,快手將持續加速大模型的研發與應用,帶來更加多元的AI創作與互動體驗。















