2024年12月19日,智源研究院發布并解讀國內外100余個開源和商業閉源的語言、視覺語言、文生圖、文生視頻、語音語言大模型綜合及專項評測結果。
相較于今年5月的模型能力全方位評估,本次智源評測擴展、豐富、細化了任務解決能力內涵,新增了數據處理、高級編程和工具調用的相關能力與任務;首次增加了面向真實金融量化交易場景的應用能力評估,測量大模型的收益優化和性能優化等能力;首次探索基于模型辯論的對比評估方式,對模型的邏輯推理、觀點理解、語言表達等核心能力進行深入分析。
智源評測發現,2024年下半年大模型發展更聚焦綜合能力提升與實際應用。多模態模型發展迅速,涌現了不少新的廠商與新模型,語言模型發展相對放緩。模型開源生態中,除了持續堅定開源的海內外機構,還出現了新的開源貢獻者。
多種模態評測綜合榜單 覆蓋文本、語音、圖片、視頻理解與生成
語言模型,針對一般中文場景的開放式問答或者生成任務,模型能力已趨于飽和穩定,但是復雜場景任務的表現,國內頭部語言模型仍然與國際一流水平存在顯著差距。
語言模型主觀評測重點考察模型中文能力,結果顯示字節跳動Doubao-pro-32k-preview、百度ERNIE 4.0 Turbo位居第一、第二,OpenAI o1-preview-2024-09-12、Anthropic Claude-3-5-sonnet-20241022位列第三、第四,阿里巴巴Qwen-Max-0919排名第五;在語言模型客觀評測中,OpenAI o1-mini-2024-09-12、Google Gemini-1.5-pro-latest 位列第一、第二,阿里巴巴Qwen-max-0919、字節跳動Doubao-pro-32k-preview位居第三、第四,Meta Llama-3.3-70B-Instruct排名前五。

視覺語言多模態模型,雖然開源模型架構趨同(語言塔+視覺塔),但表現不一,其中較好的開源模型在圖文理解任務上正在縮小與頭部閉源模型的能力差距,而長尾視覺知識與文字識別以及復雜圖文數據分析能力仍有提升空間。評測結果顯示,OpenAI GPT-4o-2024-11-20與字節跳動Doubao-Pro-Vision-32k-241028先后領先于Anthropic Claude-3-5-sonnet-20241022,阿里巴巴Qwen2-VL-72B-Instruct和Google Gemini-1.5-Pro緊隨其后。

文生圖多模態模型,今年上半年參評的模型普遍無法生成正確的中文文字,但此次參評的頭部模型已經具備中文文字生成能力,但整體普遍存在復雜場景人物變形的情況,針對常識或知識性推理任務,小于3的數量關系任務表現有所提升,大于3的數量關系依然無法處理,涉及中國文化和古詩詞理解的場景對于模型而言是不小的挑戰。評測結果顯示,騰訊Hunyuan Image位列第一,字節跳動Doubao image v2.1、Ideogram 2.0分居第二、第三,OpenAI DALL·E 3、快手可圖次之。
文生視頻多模態模型,畫質進一步提升,動態性更強,鏡頭語言更豐富,專場更流暢,但普遍存在大幅度動作變形,無法理解物理規律,物體消失、閃現、穿模的情況。評測結果顯示,快手可靈1.5(高品質)、字節跳動即夢 P2.0 pro、愛詩科技PixVerse V3、MiniMax 海螺AI、Pika 1.5位列前五。

語音語言模型,得益于文本大模型的進步,能力提升巨大,覆蓋面更全,但在具體任務上與專家模型還存在一定差距,整體而言,性能好、通用能力強的開源語音語言模型偏少。專項評測結果顯示,阿里巴巴Qwen2-Audio位居第一,香港中文大學&微軟WavLLM、清華大學&字節跳動Salmon位列第二、第三,Nvidia Audio-Flamingo,MIT & IBM LTU均進入前五。

四大專項評測榜單 多維度探索模型能力邊界與應用潛能
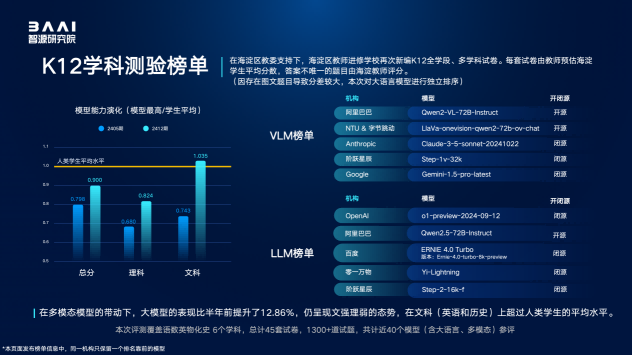
本次評測,智源研究院再次聯合與海淀區教師進修學校新編了K12全學段、多學科試卷,進一步考察大模型與人類學生的能力差異,其中,答案不唯一的主觀題依然由海淀教師親自評卷。得益于多模態能力的帶動發展,模型本次K12學科測驗綜合得分相較于半年前提升了12.86%,但是仍與海淀學生平均水平存在差距;在英語和歷史文科試題的表現上,已有模型超越了人類考生的平均分;模型普遍存在“文強理弱”的偏科情況。
FlagEval大模型角斗場,是智源研究院今年9月推出的面向用戶開放的模型對戰評測服務,以反映用戶對模型的偏好。目前,FlagEval覆蓋國內外約50款大模型,支持語言問答、多模態圖文理解、文生圖、文生視頻四大任務的自定義在線或離線盲測。此次評測,共有29個語言模型、16個圖文問答多模態模型、7個文生圖模型、14個文生視頻模型參評。評測發現,用戶對模型的響應時間有更高要求,對模型輸出的內容傾向于更結構化、標準化的格式。

作為模型對戰評測服務FlagEval大模型角斗場的延展,今年10月智源研究院推出了模型辯論平臺FlagEval Debate,對模型的邏輯推理、觀點理解以及語言表達等核心能力進行深入評估,以甄別語言模型的能力差異。本次評測發現,大模型普遍缺乏辯論框架意識,不具備對辯題以整體邏輯進行綜合闡述;大模型在辯論中依然存在“幻覺問題”,論據經不起推敲;大模型更擅長反駁,各個模型表現突出的辯論維度趨同,在不同的辯題中,模型表現差距顯著。FlagEval Debate評測結果表明,Anthropic Claude-3-5-sonnet-20241022、零一萬物Yi-Lighting、OpenAI o1-preview-2024-09-12為前三名。

此次評測,智源研究院探索了基于實際應用場景的全新方法,通過評測模型的量化代碼實現能力,探索模型在金融量化交易領域的潛在應用能力和商業價值。評測發現,大模型已經具備生成有回撤收益的策略代碼的能力,能開發量化交易典型場景里的代碼;在知識問答方面,模型整體差異較小,整體分數偏高,但在實際代碼生成任務上,模型差異較大,整體能力偏弱;頭部模型能力已接近初級量化交易員的水平。金融量化交易評測結果顯示,深度求索 Deepseek-chat,OpenAI GPT-4o-2024-08-06,Google Gemini-1.5-pro-latest位列前三。

智源評測體系FlagEval再迭代 覆蓋全球800+開閉源模型
本次評測依托智源研究院自2023年6月上線的大模型評測平臺FlagEval,經過數次迭代,目前已覆蓋全球800多個開閉源模型,包含20多種任務,90多個評測數據集,超200萬條評測題目。
在評測方法與工具上,智源研究院聯合全國10余家高校和機構合作共建,探索基于AI的輔助評測模型 FlagJudge和靈活全面的多模態評測框架FlagEvalMM,并構建面向大模型新能力的有挑戰的評測集,包括與北京大學共建的HalluDial幻覺評測集、與北師大共建的CMMU多模態評測集、多語言跨模態評測集MG18、復雜代碼評測集TACO以及長視頻理解評測MLVU等,其中與北京大學共建的HalluDial是目前全球規模最大的對話場景下的幻覺評測集,有18000多個輪次對話,和14萬多個回答。
為規避數據集泄露風險以及數據集飽和度問題,本次評測吸納了近期發布的數據集并持續動態更新評測數據,替換了98%的題目,并提升了題目的難度。

智源研究院副院長兼總工程師林詠華在評測發布會上表示,FlagEval評測體系一直堅守科學、權威、公正、開放的準則,通過技術方法平臺持續創新,打造丈量模型能力的標尺,為大模型技術生態發展提供洞察。2025年,FlagEval評測體系的發展將進一步探索動態評測與多任務能力評估體系,以評測為標尺感知大模型的發展趨勢。















